
Dear Analyst #68: Generate unique IDs for your dataset for building summary reports in Google Sheets
Podcast: Play in new window | Download
Subscribe: Spotify | TuneIn | RSS
If your dataset doesn’t have a unique identifier (e.g. customer ID, location ID, etc.), sometimes you have to make one up. The reason you need this unique ID is to summarize your dataset into a nice report to be shared with a client or internal stakeholders. Usually your dataset will have some kind of unique identifier like customer ID or transaction ID because that row of data might be used with some other dataset. It’s rare these days not to have one. Here are a few methods for creating your own unique identifiers using this list of customer transaction data (Google Sheets for this episode here).

Method 1: Create a sequential list of numbers as unique IDs
Each of these transactions is from a unique customer on a unique date for a unique product. We could do something as simple as creating a sequential list of numbers to “mark” each transaction. Maybe we can prefix this new transaction ID column with “tx-” so each unique ID will look something like this:
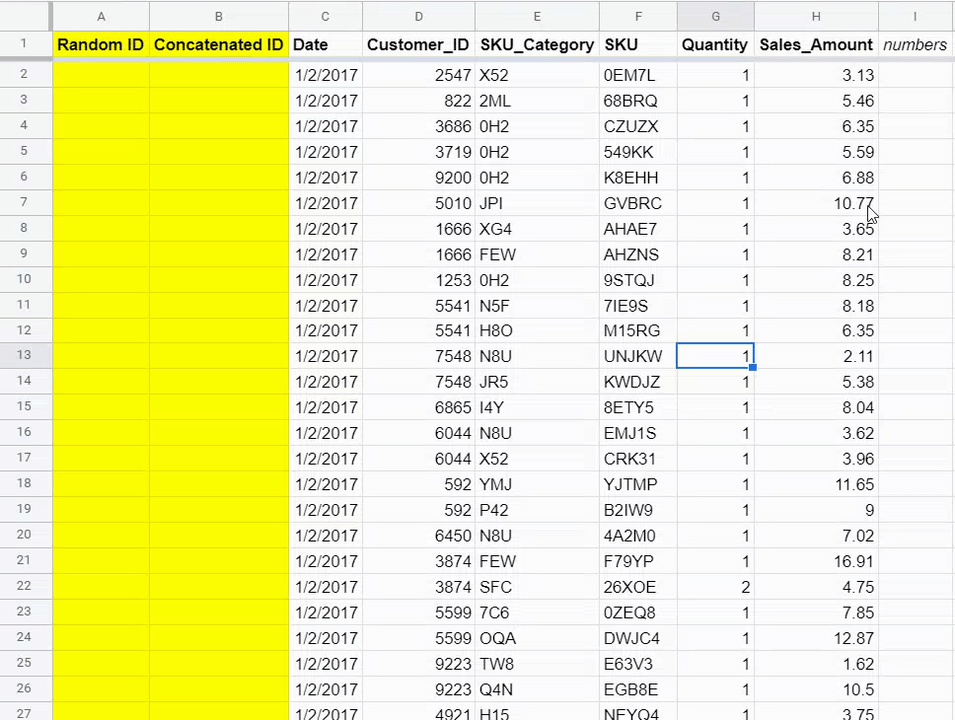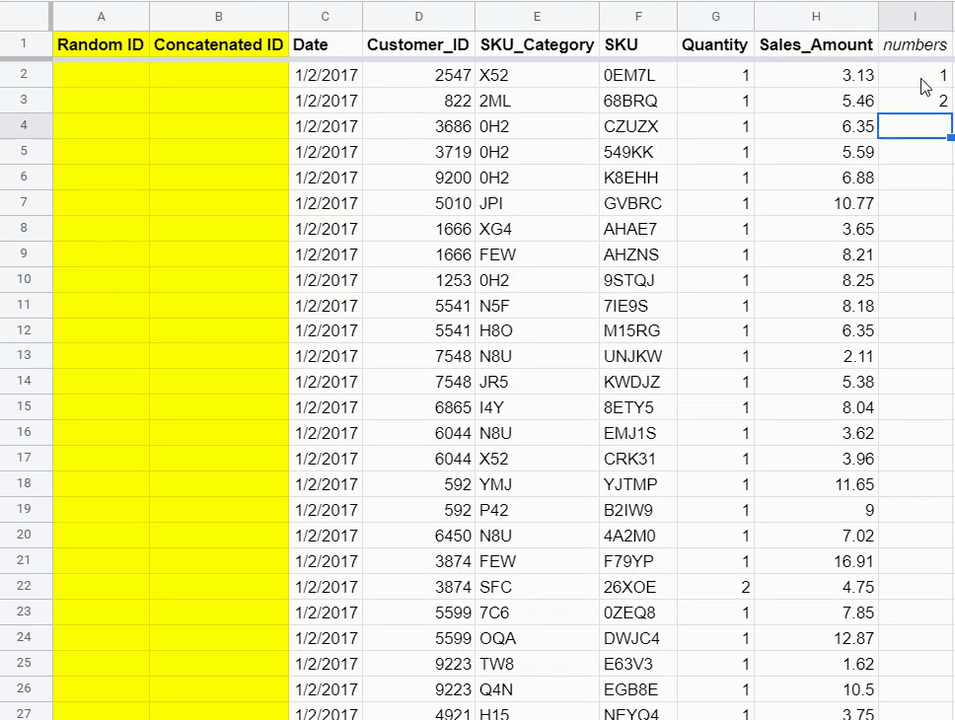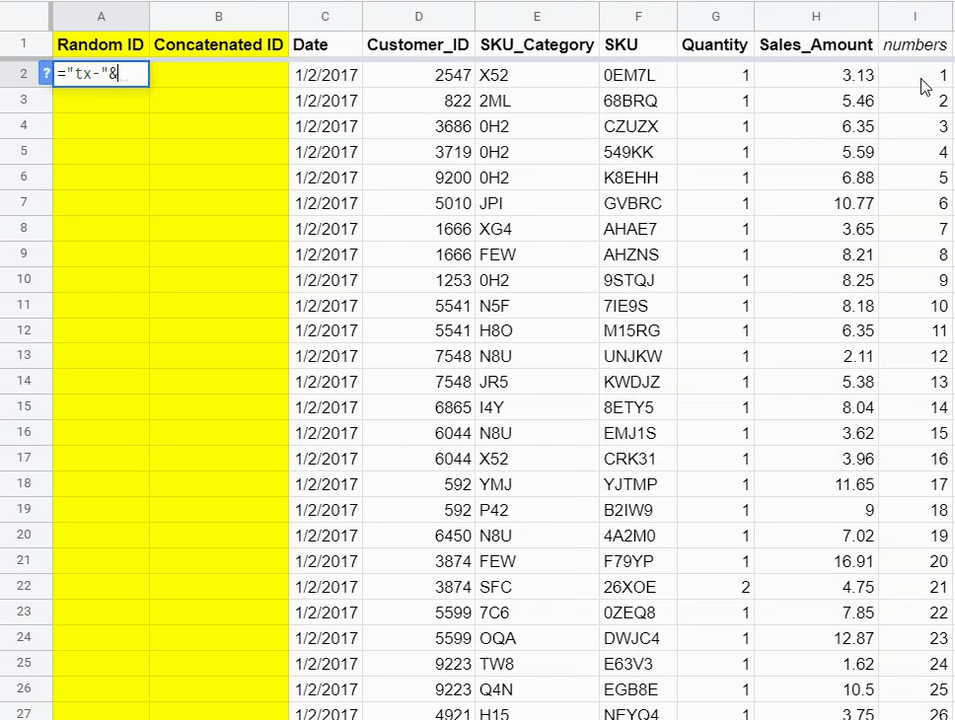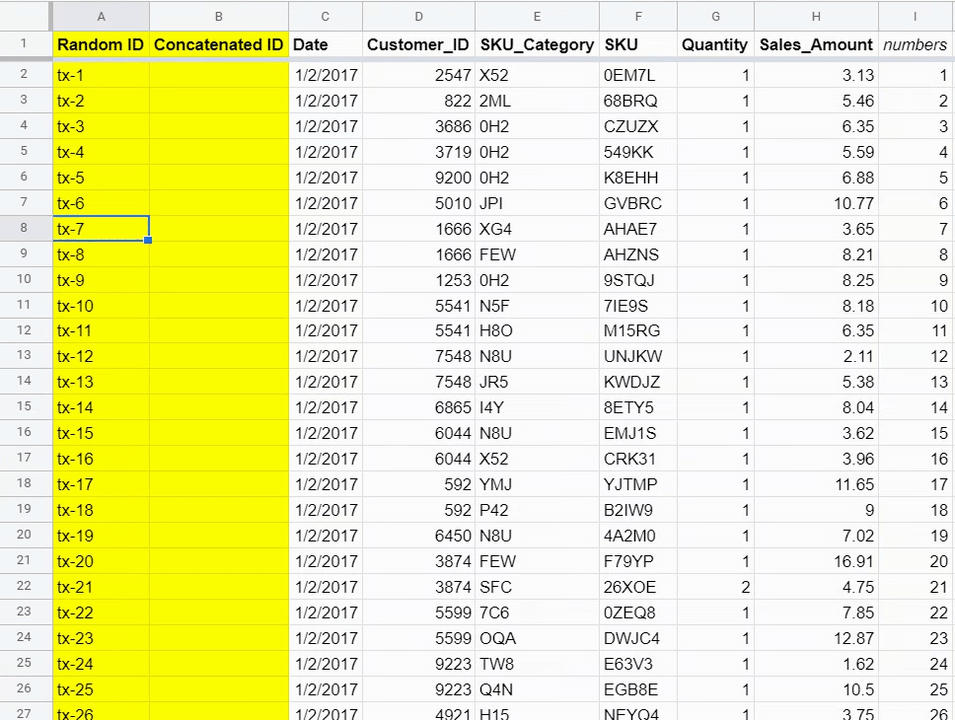
This method involves creating a dummy column (column I) of sequential numbers. Then in column A, you write “tx-” followed by the number you created in column I, and you have a unique ID. This unique ID is only relevant for this dataset, however. If there are other tables of data related to customers and transactions, those tables won’t know about this new transaction ID you just created on the fly.
Method 2: Create random numbers as unique ID
This method will make your unique IDs feel a little more “unique” since the numbers are randomized:

Notice how we happen to take the result of the RAND() function and multiply it by 100,000 to get a random number with 5 digits. Our dataset is only 1,000 rows long so the chances of duplicate values is low, but there still exists that possibility.
This is probably the least preferred solution because of the fact that there could be duplicate values (there are formula hacks to get around it). Another reason this isn’t a great solution is that you have to remember to copy and paste values from the random numbers into another column. The RAND() function is a volatile function (basically changes every time you reload the Sheet) so you would lose your unique ID every time the Sheet loads. This means you have to remember to paste just the values perhaps in the next column over before referencing that value as your unique ID.
Finally, if your dataset has timestamps like this, chances are the unique IDs are meant to be sequential (using Method 1). Assigning random unique IDs to each transaction might make reconciling the data in the future more difficult.
Method 3: Concatenate (add) columns together to create unique ID
This method involves concatenating (adding) together different columns to create a unique ID. The reason I like this method is because it makes creating reports a bit easier since you can write in the values in a cell for a lookup to reference. For instance, the unique IDs in our dataset is created by combining the Customer ID, SKU_Category, and SKU columns:

We put a dash “-” in between each of the cell references so it’s a bit easier to see all the different characters in this “unique ID.” The issue is this: what if there are multiple transactions with the same Customer ID, SKU_Category, and SKU? We insert a COUNTIF column in between columns B and C to count the number of times that unique ID appears in column B:

And then do a quick filter to see if there are any values greater than 1 in this column:

Well that sucks. Looks like we have 8 transactions that don’t have unique IDs using this method. The tricky thing with this method is figuring out what other columns can add “uniqueness” to the unique ID. The Date column can’t be used because it looks like some of these transactions happened on the same date. Maybe we can combine the Quantity and Sales_Amount columns to create a unique ID? Even that wouldn’t work because the last two rows have the same quantity and sales amount. This is where this method falls apart because as the dataset grows, you need to constantly check to see if the unique ID column you created is still in fact unique.
Great for creating summary reports
Let’s assume that we were able to create a unique ID for every transaction in this table. Now if I want to create a summary table that looks at the Sales_Amount, for instance, creating the formula might look like this:

You’re probably wondering why we would make such a complicated formula using the unique ID column versus just using the columns themselves. In the future, you might want to do a lookup to a specific transaction ID and knowing the columns that contribute to that uniqueness of that ID makes it easy to write out the hard-coded value to do the lookup.
For instance, I might know that a customer with the ID “5541” is important and I can have that Customer_ID in my summary table somewhere. Then I know that the “8ETY5” SKU is an important skew my company is tracking, and that could be another value I hard-code in my summary table somewhere. Knowing that the unique ID for the transaction includes these values might make it easier to reference that row in my summary report in the future (or perhaps in a PivotTable too).
Other Podcasts & Blog Posts
In the 2nd half of the episode, I talk about some episodes and blogs from other people I found interesting:









No comments yet.